
Embracing Chaos for Application Stability
Chaos is a science of surprises that revolves around unpredictability and unexpected outcomes. It serves as a reminder to anticipate the unforeseen, such as disrupted traffic patterns, volatile weather conditions, turbulent financial markets, etc. One fundamental principle within chaos theory is the Butterfly Effect, also known as the ripple or domino effect. This concept suggests that even an insignificant action, like a butterfly flapping its wings in New Mexico, can eventually lead to significant consequences, such as a hurricane forming in China. While the cause and effect may not be immediately apparent, the underlying connection is undeniably real. For instance, consider the scenario of an ice storm in eastern Oregon causing a power outage that affects an Amazon data center. As a result, you find yourself staring at a blank TV screen, unable to continue watching Netflix.
Figure 2. Impact of an ice storm on Netflix viewing experience
How can we effectively equip ourselves to handle such unforeseen disruptions? In the context of streaming services like Netflix, we could have taken proactive measures such as pre-downloading the content we intended to watch, switching over to network television, or engaging in other forms of entertainment, such as reading books. But what about preparing for other potential natural disasters, such as fires or earthquakes? In our daily lives, we gauge our level of preparedness by conducting drills specifically designed to simulate these scenarios, allowing us to familiarize ourselves with the necessary actions and responses.

Figure 2. A fire drill to familiarize with evacuation routes
Like the unpredictability we encounter in our daily lives, unforeseen disasters can also manifest within the realm of our corporate applications. Disruptions in the AWS cloud service were found to be responsible for a considerable number of customer incidents across various organizations each year. These incidents could have been mitigated with the implementation of chaos testing. But what exactly is chaos testing and how can it benefit us?
Chaos testing is a technique used to evaluate the resilience of an application by subjecting it to challenging and unpredictable conditions. Its main goal is to anticipate and prevent potential disruptions before they occur. By simulating chaotic scenarios, chaos testing helps us uncover vulnerabilities and weaknesses in our applications. It’s like measuring an earthquake or disaster preparedness. However, it is crucial to note that chaos testing alone does not provide solutions to address these deficiencies. Its purpose is to shed light on potential gaps, allowing us to take appropriate measures to enhance the robustness of our systems.
AWS offers the Fault Injection Simulator (FIS) to assess an application’s preparedness by allowing us to introduce errors at the service level. However, it only supports certain services such as Amazon EC2, Amazon ECS, Amazon EKS, and Amazon RDS. If you rely on AWS-managed services like API Gateway or Lambda, you won’t be able to utilize FIS. Fortunately, LocalStack comes to the rescue in such cases.
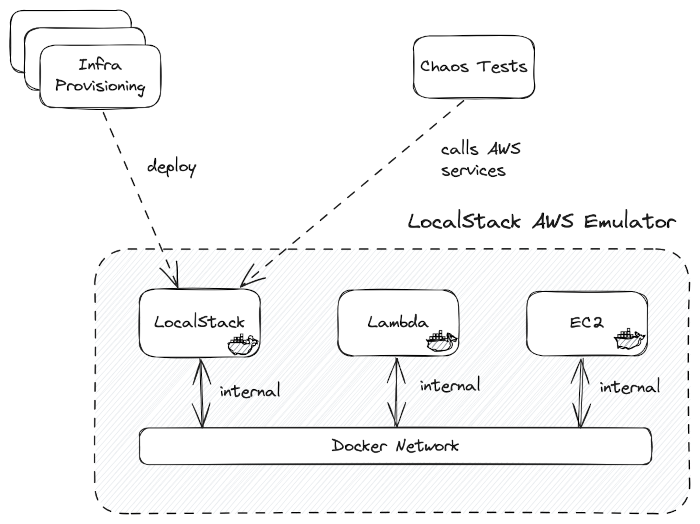
Figure 3. High-level architecture of the LocalStack environment
LocalStack provides a simulated AWS cloud environment encapsulated within a single Docker container. It allows you to deploy a wide range of AWS services, including managed services, within the LocalStack container. Once your application is deployed, you can simulate various failure scenarios by injecting faults at the service or service operation level within a specific AWS region. By injecting these faults, you can then execute a variety of chaos test scenarios to assess the resilience of your application under stress.
We’ve developed an elegant project template designed to streamline the onboarding process for applications utilizing AWS-managed services like API Gateway, Lambda, SQS, etc., in a LocalStack environment. This template boasts several key advantages: it is non-intrusive, highly customizable, and effortlessly adaptable. It seamlessly integrates with multiple GitHub repositories, ensuring a smooth workflow. It also employs a unified set of configurations for executing chaos tests locally and within the Jenkins pipeline.
name: hello
projects:
- name: hello-api
repo: my-team/hello-api
branch: main
docker-image: mycompany.com/nodejs-18:nodejs-18-chaos_4
docker-args:
steps:
- name: Prep the environment
command: /app/scripts/$REPO_NAME/prep-env.sh us-west-2
- name: Create the base infra
command: sh /app/scripts/setup-base-infra.sh us-west-2 us-east-1
- name: Replace local.tfvars files for common folder
command: rsync -av ./scripts/$REPO_NAME/services/common/ ./projects/$REPO_NAME/services/common/
- name: Replace local.tfvars files for data environment folder
Figure 4. A sample chaos configuration
Once the chaos tests are executed, comprehensive reports are generated from the test results. These reports are then conveniently uploaded to an S3 bucket for future reference. To further enhance the monitoring capabilities, we have also incorporated connectivity with LightStep and Dynatrace, enabling the collection of valuable metrics to assess the performance and stability of the application.
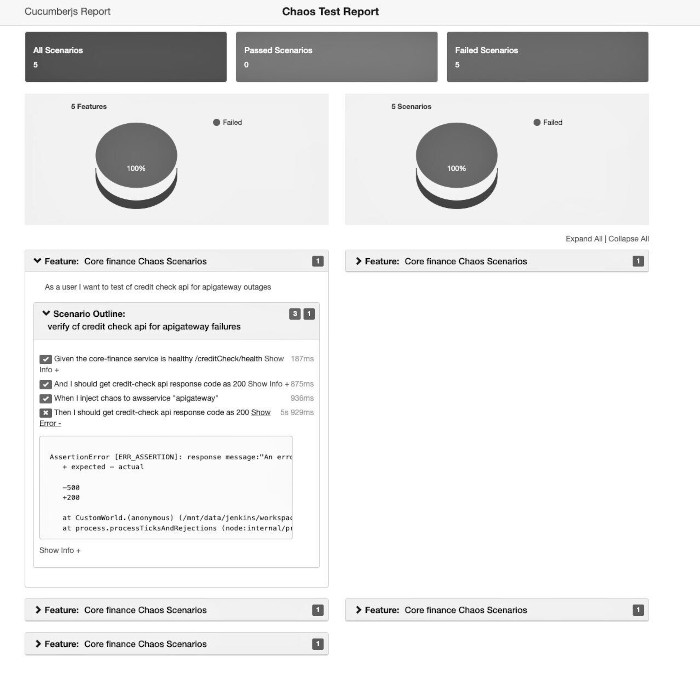
Figure 5. A sample chaos testing report
In the real world, AWS services often exhibit signs of deteriorating health before experiencing complete disruption. Rather than abruptly failing, these services may intermittently exhibit performance issues. For instance, out of ten calls made to a Lambda function, only three may fail while the remaining seven succeed. LocalStack emulates this intermittent behavior by allowing us to specify the percentage of calls that should fail during fault injection.
By simulating these intermittent failures, we can gain valuable insights into metric patterns. This knowledge can then be utilized to create alerts within a production environment. These alerts serve as early warning signs, notifying us of potential disruptions on the horizon. This information empowers us to take necessary actions, such as initiating a disaster recovery (DR) plan, to mitigate the impact of these disruptions.
While LocalStack serves as a valuable tool for chaos testing, it is important to acknowledge that it may not be a one-size-fits-all solution for every scenario. Specifically, there are certain limitations when it comes to injecting faults at the service layer for AWS services like ECS, RDS, and EKS. In these cases, LocalStack can only disrupt the API layer, while the underlying services remain unaffected.
Another limitation we encountered is related to the integration of LocalStack with Splunk as a destination for Kinesis Splunk. This constraint restricts the seamless transmission of CloudWatch logs from the LocalStack container to the Splunk environment, posing a challenge in terms of log management and analysis. Additionally, we faced issues with the EventBridge pattern matching and input transformation features while utilizing LocalStack. These functionalities did not perform as expected, requiring further investigation and potential workarounds. It is important to be aware of these limitations and challenges when utilizing LocalStack for chaos testing, as they may impact the suitability of LocalStack for certain types of application architecture.
Chaos testing serves as a valuable tool to uncover the vulnerabilities in our applications. It acts as a canary in a coal mine, alerting us to potential weaknesses. However, it is up to us to take the necessary steps to address and strengthen those areas.